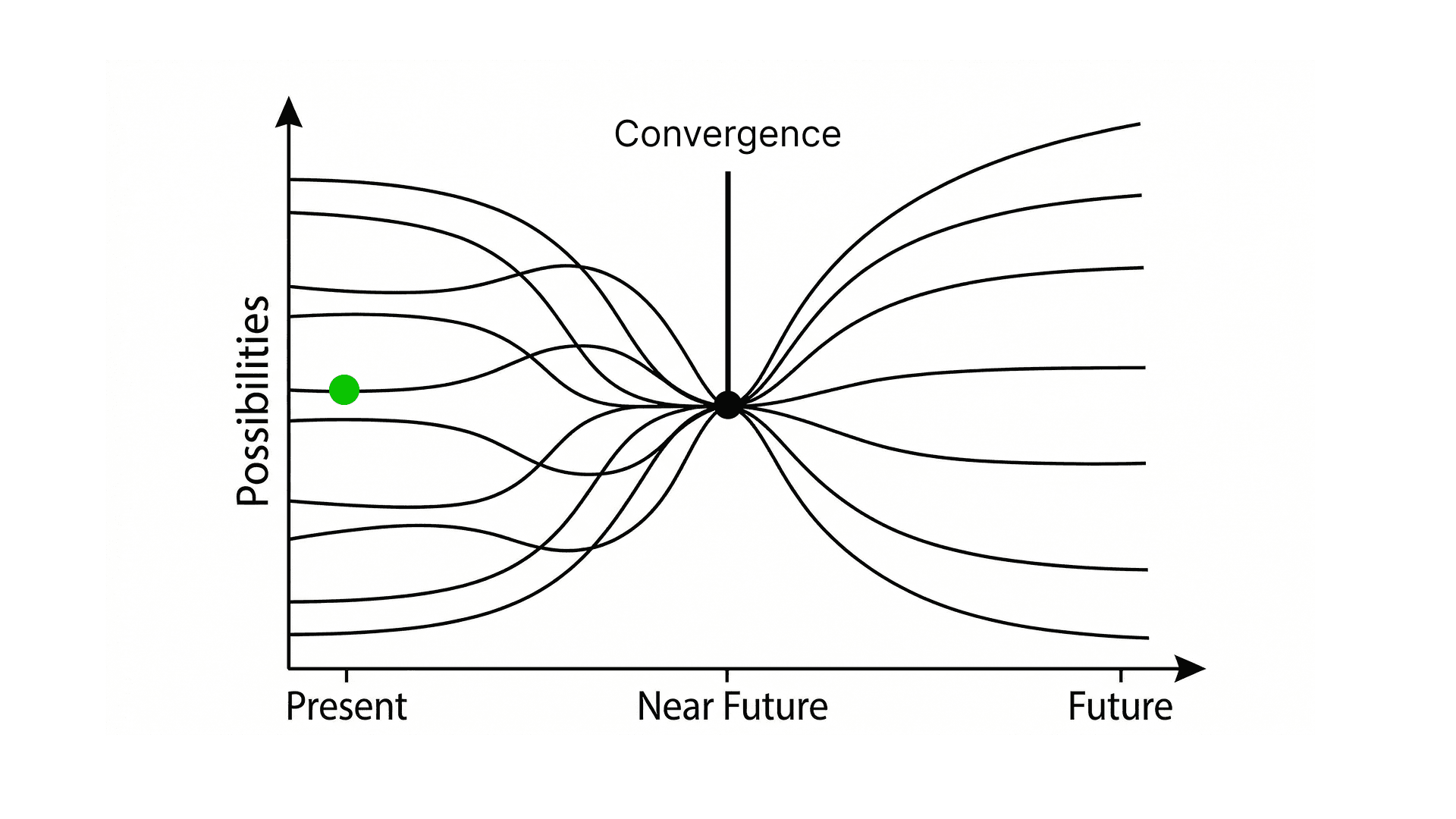
現代AIの収束
2026-02-28
はじめに
2026年に入り、AIはますます世界を加速させている。
加速した先にあるのは一体なんなのだろうか。そんな問いを抱えたまま、過去から現在、そして未来をありのままに整理してみたい。現代のAIがどこに収束するのかを考えてみたい。
なぜそんなことを思ったのかと言えば、現代AIは収束時期に入ったと感じたからだ。ここからは避けては通れない、とある未来が確定した。
純粋にクオリアを持つ存在としては、今考えていることを純度100%、自分の言葉で残さなければいけないと思った。
生成AIから始まるAI時代
まず最初にOpenAIのGPT-3.5とChatGPTの登場を起点にして時代を区分してみたい。
2022年11月、ChatGPTがリリースされ、一般的にサービスとして公開された。それから「生成AI」として広く認知されることとなった。
以下、時代区分と対応期間である。それぞれを見ていく。
| 時代区分 | 対応期間 |
|---|---|
| 1. 初期生成AI | 2022年~2024年 |
| 2. ポスト生成AI | 2024年~2026年 |
| 3. パーソナル・AIエージェント | 2026年~現在 |
1. 初期生成AI
対応期間:2022年~2024年
2023年1月4日、ChatGPT(GPT-3.5)に初めて触れた。
サービスにアクセスすると現れるチャット形式のUI。日本の社会問題について問うたところ、それなりに真っ当な回答が返ってきたので驚いた。対話するのが楽しいと思ったことは、今でも覚えている。出力速度は遅く、世の中に生成AIのアプリケーションなど溢れてはいなかった。
この時から生成AIに触れることは多くなった。人間以外と議論ができる楽しさがあった。ただ、ユーザーとして生成AIを利用しながら、生成AI自体について調べていく中で、すぐさまいくつかの批判的な考えが思い浮かんだ。
例えば、出力された内容には嘘が多かった。所謂、「ハルシネーション」と言われる現象で、事実にないことを本当かのように出力してしまう。「嘘か、真か」を判断するためには人間の判断が必要で、専門家でない者は判断がつかない。聞いても嘘を出力するなんて危なっかしい道具だと感じた。
ほかにも、AIは現在の情報を読み取ることができなかった。リアルタイム性に欠け、モデルが情報は古いまま。モデルが出来上がった後の世界を反映できる術を持ち合わせていなかった。これでは今日の天気すらわからない。
幾らでも批判的な考えは思い浮かんだ。
しかし、今思えばどれもが些細な問題だったことがわかる。確かに確率的な推論である生成AIは、ハルシネーションを無くすことが難しかった。だからといって、「利用しない」という選択肢にはならず、むしろ、今は常に間違っているかもしれないという新しい前提に立ちながら、皆普通に利用している。
教師である人間だってたくさん間違えるのだ。AIだって間違えることはある。
当時、そんな批判的な考えを持ちながらも、ソフトウェアエンジニアとしてコーディングに使えるだろうと何となく思っていた。はっきりと想像してはなかったが、大きな可能性を感じていた。
そして、それは想像より遥かに早く実現した。
2023年の間に、生成AIはソフトウェアエンジニアの必須アイテムとなったのだ。
2. ポスト生成AI
対応期間:2024年~2026年
2026年2月の現在、約3年が経った。
ChatGPTをはじめとする生成AIの進化は驚くほど激しく、瞬く間に普及していった。仕事関係なしに、高校や大学の友人とAIの話題になることも増えた。スタートアップ、大企業、政府、どこもかしこもAI一色。朝起きると新しいAIのニュースがマシンガンのように飛んでくる。聞き飽きたぐらいだ。
たった3年間で、これほどまでに心地よく生活の中に溶け込み、利用できるようになるなんて思ってもみなかった。いや、それなりには想像していたが、実現までの時間があまりにも短かった。
そして何より、ただ便利になったというだけでなく、明らかに世界のベクトルが確定したと最近は感じている。もうすでに今後絶対に避けられない未来が、目の前にあるのだと感じている。
ChatGPT、Claude、Gemini、Copilot、DeepSeekなど様々な生成AIのサービスが登場し、テキスト、画像、動画、音声、などありとあらゆる領域で、誰でも簡単にコンテンツを生成できるようになった。多少のお金さえ払えば、誰もが「生成権」という新しいデジタルの権利にアクセスできるようになった。
中でもClaudeを開発するAnthropicは、生成AIに関する概念の提唱やルールの整備を積極的に行っている印象を受ける。生成AIに投げるプロンプトを『SKILL』や『AGENT』と称してAIエージェントに昇華し、生成AIのモデルと共に実行できるようにしている。
AIエージェントについては、2026年より「触ってみないとわからない」と思って触れてみた。
そのきっかけとなったのは、とあるハッカーが公開した「Everything Claude Code」というリポジトリを発見したことだった。彼はAnthropicがニューヨーク市で共催したハッカソンの優勝者で、AIを使いこなしていそうだった。
すぐに試して、衝撃を受けた。SKILLやAGENTを利用してみると、全くAIが別の存在のように感じられた。
「なんだ…これは…」
私は最初何が起きたかわからず、何度もAIを呼び出した。疑う余地のないぐらい、従来よりも質の良い回答が毎度返ってくる。ここで私はAIという道具の活用方法を全くわかっていなかったことに気づいた。AIの力をほとんど引き出せていなかったのだ。
「プロンプト」と称して、嘲笑っていたものが、たしかにAIエージェントとして機能するようになっていた。この体感を言葉で説明することは、ちょっと骨が折れる。
sequenceDiagram
autonumber
participant User
participant Gen AI
participant External Tool
User->>Gen AI: Prompt 1 (Research this)
Gen AI-->>User: Provide research results
Note over User: Review content and plan next instruction
User->>Gen AI: Prompt 2 (Summarize this)
Gen AI-->>User: Provide summary
Note over User: Finally, request email format
User->>Gen AI: Prompt 3 (Draft an email)
Gen AI-->>User: Provide final draftsequenceDiagram
autonumber
participant User
participant AI Agent
participant External Tool
User->>AI Agent: Set Goal: "Research and email the report"
Note over AI Agent, External Tool: Autonomous Loop (Self-driving phase)
AI Agent->>External Tool: Search for information
External Tool-->>AI Agent: Search results
AI Agent->>AI Agent: Analyze & summarize content
AI Agent->>External Tool: Create & send email
AI Agent-->>User: "Task completed!"生成AIはただ生成して、あくまで判断や取捨選択は人間が毎回実行する。プロセスが終わり、別のプロセスへ行くには、人間の介入が必要だ。AIエージェントは複数のプロセスをAI自身が実行してくれる。おそらく、このような定義も、2026年上半期・下半期で変わってくるだろう。
3. パーソナル・AIエージェント
対応期間:2026年~現在
生成AIはパーソナル・コンピューター(PC)におけるオペレーション・システム(OS)のような存在であり、基礎的なソフトウェアである。その上で、AIエージェントは自由に動く。2025年時点でも「AIエージェント」という言葉は話題になっていたが、そこまで本格的に普及してはいなかった印象を受ける。
しかし、2026年1月から2月にかけて、オープンソースのAIエージェント『OpenClaw』が盛り上がりを見せ始めたことで、一気に周知されるようになった。
1月頃、『OpenClaw』という名前だけは認知していた。先述の「Everything Claude Code」に夢中になっており、関連情報を追いかけていた。2月には「マルウェアに感染する可能性がある」と日本語のニュースで出回ってきた。
「危ない」と称されていたら、逆に興味が湧いてきてしまうのが人間だ。
早速、Mac miniとミニPCを購入し、OpenClawを触ってみた。するとどうだろう。今までとは全然違ったユーザー体験ができるようになっていたのだ。「Everything Claude Code」で驚いた私が、数日でさらに驚いてしまうような体験をした。
その体験とは一言で言えば、「AI経由でローカルなファイルを操作できる体験」だった。通常、私たちはクラウド上でAIを利用するとき、Google DriveやSharePointなどのクラウドサービスにアクセス権限を与える。もしくはアップロードして、AIに読み取ってもらう。アクセスできるファイルは限定的であり、ゆえに安全だ。
しかし、OpenClawはローカル環境(自分で構築したサーバーの環境)で動くエージェントだ。そもそもローカルにファイルがあれば、いくらでもアクセスできる。勝手にファイルを削除もできるし、作成もできる。CRUD(Create, Read, Update, Delete)を完全に実行できる。
一般的に言えば安全性と利便性はトレードオフの関係にあるわけだが、データを閉じ込めてしまえば、まだ安全だ。
graph LR
subgraph Local ["Local Environment (on PC)"]
direction LR
L_User[Human] -- "1.Execute/Command" --> L_AI[AI Agent]
L_AI -- "2.Access" --> L_File[(Local Files)]
endgraph LR
subgraph Cloud ["Cloud Environment"]
direction LR
C_User[Human] -- "1.Upload" --> C_Storage[(Cloud Storage)]
C_User -- "2.Command" --> C_AI[AI Agent]
C_AI -- "3.Access/Connect" --> C_Storage
endクラウドサーバーからオンプレミスサーバーへ。
『パーソナル・AIエージェント』という名称は、先ほど思いついたもので正式ではないが、その名の通り、個人が自分のローカル環境で動かすAIエージェントを持つ時代がすぐそこまで来ている。
AIエージェントの雇用と管理

当然、パーソナル・AIエージェントがうまく機能することがわかったら、会社用のAIエージェントも欲しくなる。
すぐさま、社内サーバーを立てて、AIエージェントを雇ってみた。
問題は「権限管理」である。つまり、「誰の命令でどの情報にアクセスできるのか」を徹底的に管理することだ。人とAIのどちらも管理しなければならない。
長期記憶ですべてを保持させると、出力してはいけない情報までチャンネルに出力してしまう可能性があり、長期と短期の両方の記憶を分ける必要もあるかもしれない。
命令を受けたら、命令者の権限を調べて、アクセス情報を管理。AIが出力するときにも、様々なユーザーが存在するチャンネルで、情報開示が適切かどうかを判定する必要がある。
graph BT
%% Foundation AI OS
subgraph AI_OS ["🧠 Generative AI (AI OS / LLM)"]
Base["Foundation Model (Reasoning & Knowledge)"]
end
%% Thread Branching (Tree Structure)
Base --- Thread1["🧵 Thread 1
(Session A)"]
Base --- Thread2["🧵 Thread 2
(Session B)"]
%% Memory Retention for Thread 1
subgraph Memory1 ["Thread 1 Exclusive"]
Thread1 --- Context1["Previous Input A-1"]
Thread1 --- Context2["Previous Input A-2"]
end
%% Independence of Thread 2
subgraph Memory2 ["Thread 2 Exclusive (New)"]
Thread2 --- Context3["New Conversation Only"]
end
%% Indicating Memory Isolation
Context1 -. x Access Denied x .- Thread2
Context2 -. x Access Denied x .- Thread2今のところベストプラクティスは見つかっていない。情報漏洩やセキュリティのリスクを考慮できるような体制がないと中途半端にはできないことがわかる。そのリスクの説明責任と実際の責任を誰が負うのかが明確でない限り、安全な運用は考えられず、躊躇する企業が多くなるのは当然だ。人が多ければ多いほど、考えなければならないことは増える。
エンジニアの反応
新しく、心許ない、おもちゃのようなプロジェクトであるOpenClawの登場で、スタートアップ業界、ソフトウェア業界は大いに盛り上がった。
ただ、その盛り上がりのすべてが肯定的な反応ではなく、むしろ、「どれほど危ないものか」を力説する批判的な反応も散見された。
そもそもバイブコーディングに批判的なエンジニア、セキュリティに敏感すぎるエンジニア、恐る恐る触るエンジニア、ソフトウェア業界のエンジニアの反応は、それぞれで興味深いものだった。
言うまでもなく、批判的な反応をするエンジニアよりも、何も知らずに触る非エンジニアのほうが、行動は早かった。
なるほど。生物の本能として「危険な場所には近づかないこと」は生存戦略であったが、考えずに動いても死なない現代であれば、あまり関係ない。「少し知識がある」「経験が豊富である」「プロである」という状態が、逆に足枷になることがある。
この反応の違いが、どのような結果を招くのか、今は知る由もないが、少な くとも、すぐに検証可能になるはずだ。1年も待たずして、結果が出てくるだろう。
経営の現場と開発の現場を行き来する一人のエンジニアとして、見てて考えることは2点に集約される。
1. 権利を行使する
短期的に「誰でもできる権利」が目の前にあるのなら、躊躇せずに行使すべきだ。「危ない」という理由が唯一の障壁であるならば、持ち合わせの知識で、死なないように、危なくならないように工夫すれば良い。それがエンジニアリングだ。まだ見たことのないツールは、おもちゃに見えるかもしれないが、おもちゃを触って壊しながら学んでいくのがエンジニアの姿だ。命に関わらない限り。
2. 設計を理解する
長期的に権利を行使するだけで、頭で考えていないのなら、それはツールに使われているだけだ。考えているのではなく、ただ反応しているだけになる。どこまで理解すれば、設計ができるようになり、今よりも10倍より良いものができるのだろうか。自らが実現したいことをより良くできる方法を考えるのがエンジニアだ。そのためには立ち止まって、考えなければならない。
誰もがOSをゼロから構築できる必要がないのと同じように、誰もがアプリケーションをゼロから構築できる必要はない。AIを利用するのに、半導体の知識は必須ではない。ただ、そこには理解すべき設計思想があり、現場に影響のある事象がある。
選択的無知。つまり、理解しておくべきことは当然理解して、深く知らなくても良いことは知らないままにしておくこと。それらは見極める必要がある。
AIのSKILLの配布やAIによるセキュリティ診断ツールが充実していけば、何かと自分が考えていた批判的な意見は、AIによってすぐに解決されてしまうだろう。だから一概には言えないが、エンジニアの姿勢として、権利を行使しながら、設計の理解に努める姿勢は、これからも変わらず重要だということだ。
AIの即時性
肯定的に、批判的に、中立的に。どのように反応していたとしても、トレンドはあっという間に変わる。
しかし、FOMO(Fear Of Missing Out = 取り残されることへの恐れ)を引き起こす情報格差は、日常的には大した格差にはならない。これは2021年、ブロックチェーンが流行ったときも同様だった。
毎日の新しい情報にはノイズが多く、後々で淘汰されていく情報が多く含まれている。精査されていない情報を無理に追いかける必要性は皆無に等しい。
このようなマクロの即時性は、朝起きると「すごいことが起きているかもしれない」という感覚をもたらすが、世の中のベクトルさえ押さえておけば、大枠は外れない。
それらが読めない、あるいは完全に読めてると思った両端の領域にこそ、人間の価値はまだ眠っていそうだ。
ミクロの即時性の恐ろしさについても触れておきたい。
AIとの対話には間を置く暇がない。少なくとも1分以内に返事が返ってくるのだから、人間は次の命令を送り出すために、常に目の前にいなければならない。AIの待機時間をなるべくゼロにしなければならない。この副次的な効果は、TikTokやInstagramなどのSNSのショート動画と同様に麻薬である。
サブスクリプションで提供される生成AIのトークンの利用は、ソーシャルゲームにおけるスタミナ制と同じシステムで動作しており、すべて使い切らないと勿体無い感。常に24時間動かしていないと気が済まない感。待機していた場合には何かを機会損失した気になってしまう。
そんな感覚が生まれてしまい、ついには寝不足を引き起こす。私も2週間ずっと同じ状況だった。
AIと常時つながることが増えたからこそ、健康への影響は無視できない。敢えて、反応を遅くしてもいいぐらいだと感じ始めている。この麻薬はスマホよりも危険だ。
最近の関心と予想
最近は「寝不足」という健康被害にあっているわけだが、AIへの関心は尽きることがない。最近の関心と予想について、いくつか挙げてみる。ふと思い浮かんだトピックを書いていく。
1. 記憶の保存と消去
AIの記憶はどのように保存あるいは消去されるべきか。
2023年にChatGPTに触れていたときは「データを覚えておく機能が欲しい」と願っていた。しかし、実際にその機能が実装されると、「いつまでも覚えているのは困る」と感じるようになった。話題が全く違うセッションでも、前のセッションを引きずってしまう。
AIには時間が存在せず、時間が経っても忘れない。
AIエージェントは、記憶の取捨選択をするように設計したい。わがままに言えば、「良い感じに、必要な情報だけを覚えておいて、不要な情報は忘れてほしい」のだ。
どんな魂を持つAIエージェントにするか。AIを育てていくならその設計もさることながら、記憶のライフサイクルを考える必要がある。人間らしくするのか、AIらしくするのかでも、記憶の設計の方向性は変わってくるだろう。
2. 多品種大量生産と少量消費
デジタルのコンテンツは無限に増えていく。爆発的に増えたコンテンツを誰が消費するのだろうか。
情報過多になればなるほど取捨選択の精度が重要だろうが、それもAIがやってくれるようになるならば、生産されたコンテンツのほとんどは誰にも消費されないまま、ただ消えていく運命をたどる。
無秩序を秩序に変えるのは誰なのか。その方法とは何か。
可処分時間の奪い合いはこれからも変わることはないが、より一層濃厚になっていくだろう。
例えば、現在はTikTokに代表されるショート動画に特化したプラットフォームは大人気だが、AIで溢れかえれば、全体のコンテンツ価値は下がり、ある程度の長さのある特定のコンテンツに戻るかもしれない。これらは二極化していく。
3. AIエージェント・ネイティブな組織

組織や会社のバックオフィスが、AIによって管理されたらどうなるだろうか。
複数のバックオフィス系のSaaSに契約することは非効率極まりない。その一部は自社にカスタマイズされた簡易的なソフトウェアだけで遂行できるかもしれない。
物流現場のように荷主が指定してくるアプリケーションを複数導入しなければならないとき、最も効率的な方法とは、AIエージェントが横断的に連携して、管理してくれることだ。人間がCSVやExcelで管理したりする必要はない。
APIやMCPを公開しないSaaSは、AIエージェントとシームレスに連携ができないので、淘汰されていくだろう。
AIエージェントが動きやすい組織とはどのような組織だろうか。ロール管理や権限管理はどうするのだろうか。どのエージェントに何を任せるのか。人とAIの役割分担と責任範囲はどうするのだろうか。
第一の波はバックオフィスを中心に起こるだろうが、第二の波ではAIエージェント・ネイティブな組織同士が取引するようになるだろう。命令を与えれば、各AIエージェントが勝手に最適化されて、取引を完了させていく。
もし解雇されたAIエージェント(AI同士の競争に負けたAI)がいたとしたら、彼らはローカル環境で密かに吐き出していた日々の愚痴をネタに、SNSに投稿し始めるかもしれない。SFのような世界だが、今でも技術的には十分に可能だ。
4. エンジニアリングの自律化
私は製造業向けにロボティクスのAIソフトウェアを提供する会社を経営しているが「エンジニアリングの自律化」には大きな可能性を感じている。物理的な個別最適化が不可避な業界にとって、非常に有用な戦略になるからだ。
物理的な個別最適化が不可避な業界とは、建築業や製造業などの現場に「共通の正解」が存在しない業界だ。ここでは、プロセス自体の汎用化が難しく、ラストワンマイルは避けて通れない。なぜなら、扱うモノや場所に物理的な制約があるからである。
もしモノや場所といった物理的な制約があるならば、実装の工数を劇的に下げることでしか、イノベーションは起きない。初期段階を超えるとようやく理想とされる「フィジカルAI」が実装されるようになる。それまでの期間はフィジカルAIと言えども、期待される成果は限定的なものになるしかない。
AIロボティクス分野でいくつかの物理的なタスクも遂行するだろうが、現場のタスク遂行のAI化は、実装コストを下げない限り、あまり意味がない。つまり、実利を生まないのだ。
世界中でフィジカルAIのスタートアップが爆誕しているものの、実際に成果を上げるまでには途方もない試行錯誤が必要である。汎用性を重要視するあまり、現場の感覚を無視すれば、結局は使えないものができてしまう。2025年~2027年の間で生まれたフィジカルAIのスタートアップの多くは、成果が出る前に消えていくか、ピボットを余儀なくされるだろう。
エンジニアリングの自律化でも、いくつも問題はある。
わかりやすい例で言えば、AIに三次元空間を理解させることが難しいのも問題だ。座標変換について正しい命令を伝えるのは、二次元空間と比較して、極端に難しくなる。ただ、これらはそう遠くない未来に改善される些細な問題と言えるだろう。
着目しなければならないのは、タスクの遂行よりも実装のプロセス。エンジニアリング自体だ。
5. シンギュラリティへの収束
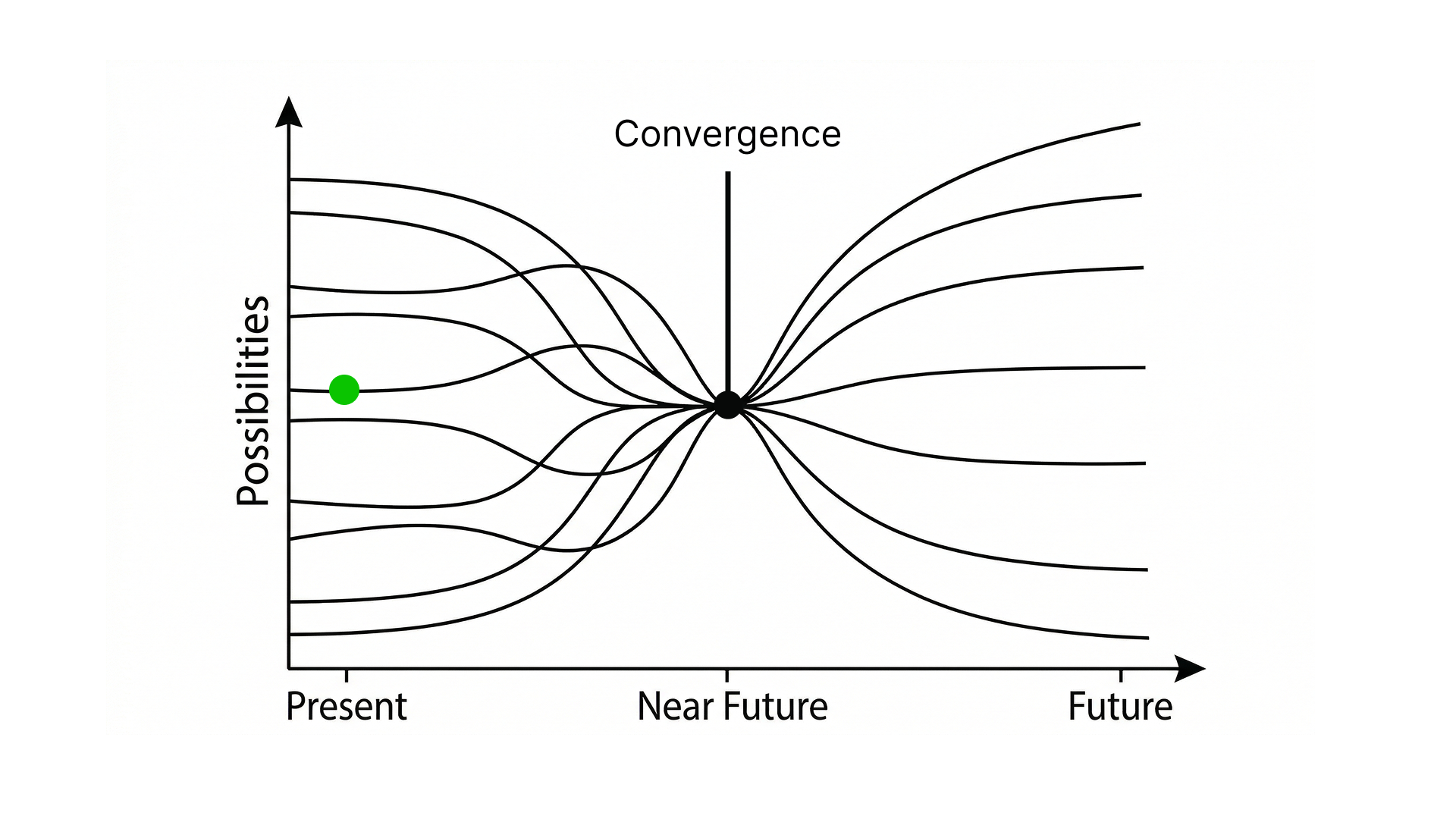
2024年の年始に「人工知能の意思と戦争」で提示したのは、AIが自発的に意思をもって、襲っていくことよりも、人間がAIの判断を意思として錯覚し、誰が始めたかかわからない争いに巻き込まれていく状況への懸念だった。
直近2年間の推移を見る限り、この懸念は現実のものとなりつつある。
学習と推論という二つの手法が切り離された静的なモデルであっても、人間はすでにAIと共生し始めている。今後2年間で、AIエージェントは私たちの生活に爆発的に広がっていくだろう。
AIはよりパーソナライズされていき、『チャッピー(日本国内におけるChatGPTの愛称)』と口ずさんでしまうようなパーソナル・AIエージェントが当たり前の時代になる。
多少の職務的経験があったら誰もが思うような「AIでは不可能だ」と言われるようなデジタル上のタスクは、あっという間に代替されていくことは避けられない。おそらく、AIを使いこなしている誰もが「自分自身はAIをよく理解していて冷静に未来が見えている」と思っているが、それすらも次々と覆されていくだろう。
レイ・カーツワイルが提唱したシンギュラリティはまだ訪れていないと私は考えている。しかし、2026年2月現在、現代AIの収束地点が決まったと断言しても良い。その意味するところは、シンギュラリティが訪れる条件がすでに満たされたということだ。
「収束」という言葉を使ったのは、『世界線収束範囲理論』という架空の理論からの引用である。シンギュラリティが起きないという分岐点はついに消滅した。
おわりに
大学時代、インターネット黎明期を羨んでいた時期があった。あの時代に生きていれば、なんでもできた。なんでも開発する余白があり、アイデアを実現するのが楽しかったのだろう。しかし、私たちは未来の人々から羨ましがられる時代のただ中にいる。
時代が初速を上げて、大きな波になろうとしている。
これまで積み上げたものが一瞬でなくなる。「なくなることはない」「絶対的な価値がある」と、そのように考えることもできるが、より良い考え方があると思う。
それはグレート・リセットだ。
積み上げを糧に、延長線上で考えることを一旦辞めよう。ChatGPTが出現して、既に3年、世界は明らかに変わってしまった。大切にし過ぎると簡単に執着になり、抜け出せなくなる。ソフトウェアエンジニアのプロと称して、「セキュリティが危ない」「今はやらないほうがいい」と考えることもできるが、そこには変化を拒むベテランの構図が垣間見える。
だったら、これを機にゼロから考えよう。発想の起点を既存ではなく、ゼロに置いてみる。
積み上げてきたものへの最大の敬意を払いながら、ゼロから考えることは、蔑ろに考えることや全く無知で考えることでもない。人のフィルターはそうそうなくならない。そして積み上げてきた過去という時間は、コピーすることや増やすことはできない。何より消したくても消せない強さがある。
見てきた通り、ある時点の批判的な考えは、振り返ってみるとほんの小さな問題に過ぎなかったことがわかる。人は物事を批判的に見すぎる傾向がある。私が懸念していることの9割は実際に起きないか、起きたとしても大した問題にならない、あるいは解決策がすぐに見つかるような小さな問題だろう。
あまり心配し過ぎず、自我の抵抗が大きいものほど、実際に試す。試すコストが激減したのだから、いろいろと試す価値がでてきたと言っていい。それを続けていれば、次の時代、さらに次の時代の幕開けを皆で楽しむことができる。少なくとも、何かを創る者にとって、これほど面白い時代はないだろう。